- 25 novembre 2025
Un modèle d'IA pour prédire le goût des aliments
Michiel Schreurs, doctorant et orateur principal au Food Process Seminar

Michiel Schreurs, chercheur doctorant au Centre de microbiologie VIB-KU Leuven, a commencé sa présentation par une constatation: le goût est l'une des propriétés les plus fondamentales, mais aussi les plus difficiles à cerner dans l'industrie alimentaire. Bien que les entreprises investissent depuis des décennies dans la technologie analytique et le contrôle des processus, l'évaluation du goût reste largement tributaire des panels humains.
Prédire le goût: de manière plus cohérente et plus efficace
Ces panels fournissent une image riche et nuancée de l'expérience des consommateurs, mais ils posent en même temps des problèmes majeurs: ils sont coûteux à organiser, prennent beaucoup de temps et, surtout, sont intrinsèquement variables. Il n'y a pas deux panélistes qui ont le même goût, et la même personne n'a pas le même goût à des moments différents. Selon Michiel Schreurs, cette nature subjective n'enlève rien à leur valeur, mais elle crée une demande permanente de méthodes permettant de prédire le goût de manière plus cohérente et plus efficace.
Qui est Michiel Schreurs?
Michiel Schreurs est doctorant au Centre de microbiologie VIB-KU Leuven à Louvain, dirigé par le professeur Kevin Verstrepen. Il étudie la manière dont la composition chimique de la bière détermine le goût qui l'accompagne, en se concentrant plus particulièrement sur la mesure dans laquelle nous aimons la bière (sans alcool). Son travail associe la chimie analytique à la recherche sensorielle en utilisant l'apprentissage automatique.
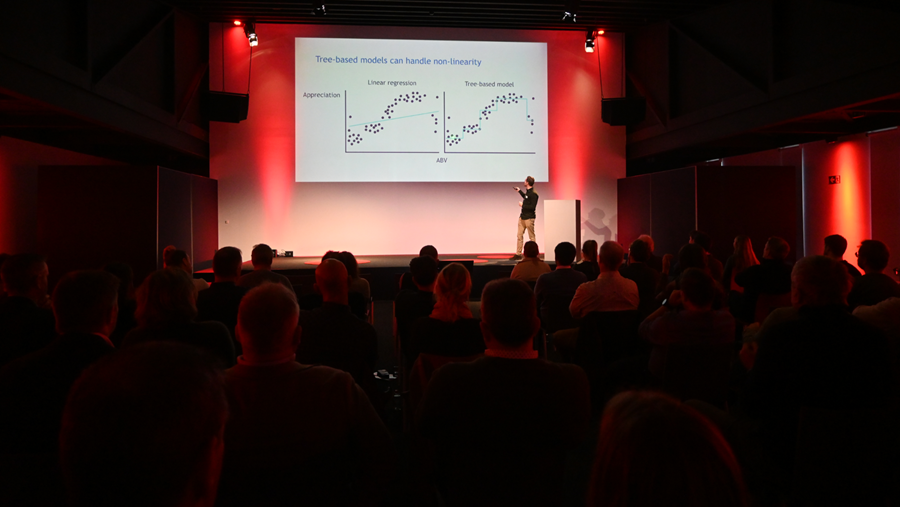
 Selon Schreurs, il existe une tension entre les statistiques classiques et la réalité des données gustatives. L'industrie alimentaire travaille depuis des années avec des modèles de régression pour relier le goût à des données chimiques ou à des paramètres de processus. Toutefois, ces modèles sont simplificateurs: ils supposent des relations linéaires, des effets monotones et des interactions limitées entre les variables.
Selon Schreurs, il existe une tension entre les statistiques classiques et la réalité des données gustatives. L'industrie alimentaire travaille depuis des années avec des modèles de régression pour relier le goût à des données chimiques ou à des paramètres de processus. Toutefois, ces modèles sont simplificateurs: ils supposent des relations linéaires, des effets monotones et des interactions limitées entre les variables.
En réalité, le goût est un phénomène hautement non linéaire. Deux composants qui, pris séparément, ont peu d'effet peuvent soudainement se combiner pour créer une impression gustative prononcée, tandis que d'autres combinaisons se masquent complètement l'une l'autre. Ces interactions complexes sont difficiles à saisir dans les modèles traditionnels, de sorte que les prédictions sont souvent inexactes ou incohérentes.
Apprentissage automatique
À partir de ce goulet d'étranglement, le groupe de recherche auquel appartient Schreurs a présenté l'apprentissage automatique comme une alternative prometteuse. Il a souligné qu'il ne s'agit pas de boîtes noires impénétrables, mais de modèles qui s'adaptent mieux à la structure sous-jacente des données.
Les arbres décisionnels sont au cœur de l'étude. Ces modèles divisent les données de manière répétée en sous-groupes plus homogènes, en intégrant naturellement les effets non linéaires et composés. "Ces techniques, malgré leur réputation, ne sont pas nécessairement plus complexes que les statistiques classiques. Elles suivent des principes différents, mais sont souvent intuitives sur le plan conceptuel et nécessitent une évaluation particulièrement minutieuse", affirme Schreurs.
Plus de quatre cents bières
L'étude proprement dite est partie d'un vaste ensemble de données comprenant plus de quatre cents bières disponibles dans le commerce. Chaque bière a fait l'objet d'une analyse chimique approfondie et a été dégustée par deux sources totalement différentes: un panel de dégustateurs formés en interne et un large groupe de consommateurs par le biais d'avis en ligne. En combinant les données du panel avec celles des consommateurs, le groupe de recherche a pu aborder deux questions simultanément: est-ce que les modèles peuvent prédire les perceptions du goût et est-ce que la source des données affecte les performances?
Schreurs a expliqué comment l'ensemble des données a été divisé, en précisant qu'une séparation adéquate entre les données d'entraînement et les données de test est essentielle pour développer des modèles fiables. Des paramètres chimiques et des évaluations de goût ont été collectés pour chacune des plus de 400 bières. Une proportion fixe de ces bières - généralement de soixante à quatre-vingts pour cent - a ensuite été affectée à l'ensemble d'entraînement.

C'est à partir de ce sous-ensemble que le modèle apprend quels motifs chimiques correspondent à des goûts particuliers. Les bières restantes ont été complètement exclues du processus de formation et ont constitué l'ensemble de test. Cet ensemble de test sert en quelque sorte d'examen: le modèle n'a jamais 'vu' ces bières auparavant et doit donc prédire comment elles se classeraient sur différentes dimensions gustatives en se basant sur les connaissances qu'il a acquises.
"Cette approche est nécessaire pour éviter l'overfitting", explique Schreurs. "Un modèle qui correspond trop précisément aux modèles spécifiques des données d'apprentissage, mais qui perd cette même précision avec de nouveaux échantillons, semble fonctionner parfaitement pendant l'entraînement, mais échoue dès qu'il doit être appliqué dans un contexte industriel réel. Le fait de diviser strictement l'ensemble de données et de ne le tester qu'à la toute fin permet de savoir si le modèle est réellement généralisable."
Pas de modèles de données accidentellement favorables
Il existe donc des différences évidentes entre les méthodes statistiques classiques et l'apprentissage automatique: les modèles linéaires semblent donner d'assez bons résultats pendant la formation, mais s'effondrent sur l'ensemble des tests, tandis que les modèles arborescents conservent largement leurs performances.
Le groupe de recherche a utilisé la validation croisée répétée pendant la formation, en divisant plusieurs fois l'ensemble de formation en sous-ensembles plus petits. Cela permet d'éviter que les fluctuations aléatoires des données ne conduisent à une surestimation de la qualité du modèle. Un modèle n'a été utilisé sur l'ensemble de test final que lorsqu'il a obtenu des résultats cohérents dans tous ces tests répétés. Cela a permis à Schreurs et à son équipe d'attribuer avec plus de certitude les résultats au pouvoir prédictif réel du modèle et non à des modèles de données accidentellement favorables.
Une base pour des applications fiables dans l'industrie alimentaire
Selon Schreurs, cette méthodologie n'est pas seulement pertinente pour la recherche, mais constitue également la base d'applications fiables dans l'industrie alimentaire. Les entreprises qui souhaitent intégrer l'apprentissage automatique dans leur contrôle de la qualité doivent maintenir la même discipline: aucun modèle ne doit être jugé sur des données qu'il a déjà vues pendant l'entraînement. C'est la seule façon de prédire comment un modèle se comportera lorsqu'il sera déployé dans un environnement de production.
Selon Schreurs, les résultats ont montré un contraste frappant entre les différentes dimensions du goût. "L'appréciation globale d'une bière, qui est souvent fortement influencée par les préférences personnelles, s'est avérée étonnamment prédictive. Toutefois, ce n'est qu'en utilisant la grande quantité d'avis en ligne que l'on peut prédire le goût d'une bière. Les panels internes, bien qu'entraînés, se sont révélés trop peu nombreux pour générer un signal aussi robuste. La variation au sein du groupe était trop importante par rapport au nombre de dégustateurs, de sorte que le modèle était moins apte à reconnaître des modèles fixes."

Techniques d'interprétation
Pour des composantes gustatives plus spécifiques, telles que la perception de l'alcool, les résultats ont été extrêmement bons, selon Schreurs. Les modèles sont parvenus à prédire presque parfaitement, avec des valeurs au carré, le goût alcoolisé d'une bière, ce qui constitue une avancée considérable par rapport aux approches de régression traditionnelles. Selon lui, cette performance élevée s'explique en partie par le fait que les perceptions telles que l'alcool dépendent moins des préférences individuelles et sont plus fortement liées à des composants chimiquement mesurables.
Pour renforcer la confiance dans ces modèles, son groupe de recherche a travaillé intensivement sur des techniques d'interprétation qui permettent de comprendre comment le modèle arrive à une prédiction particulière. Grâce à des méthodes analytiques, l'équipe a pu visualiser les substances chimiques que le modèle considérait comme déterminantes pour un goût spécifique. Selon Schreurs, ces informations ne sont pas seulement intéressantes d'un point de vue académique, mais ont également une valeur ajoutée pratique.
Les modèles ont réussi à prédire presque parfaitement, avec des valeurs au carré, le goût alcoolisé d'une bière, ce qui constitue une avancée considérable par rapport aux approches de régression traditionnelles
Lors d'expériences au cours desquelles certains composants ont été ajoutés à des boissons non alcoolisées, les modèles se sont avérés pointer dans la bonne direction: les ajouts qui, selon le modèle, renforceraient l'impression d'alcool se sont avérés être effectivement le cas lors des tests sensoriels. Les résultats du modèle ont ainsi été confirmés expérimentalement, ce qui constitue une étape importante pour convaincre les partenaires industriels.
Contrôle de la qualité et détection des fraudes
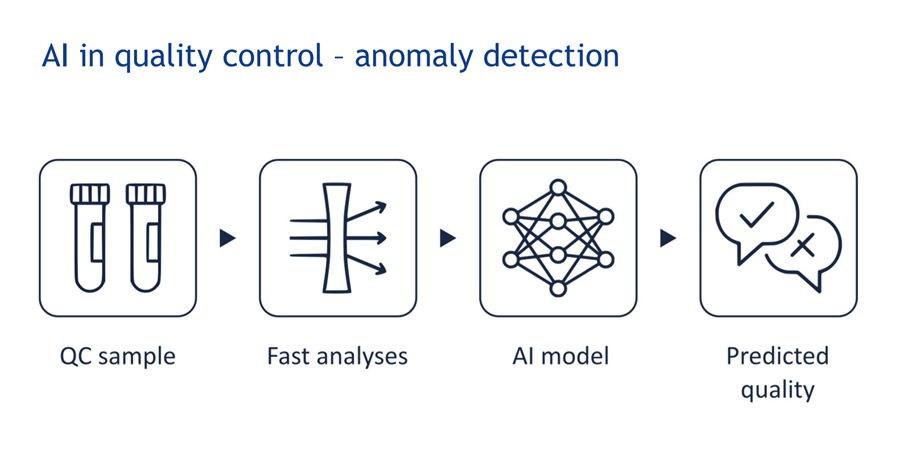
Schreurs voit des possibilités d'application dans plusieurs domaines. Le contrôle de la qualité, dit-il, est une première étape évidente. De nombreuses entreprises disposent de vastes ensembles de données historiques contenant des analyses chimiques, des variables de processus et des évaluations de goût associées. "C'est exactement dans ces circonstances que l'apprentissage automatique peut exceller: en découvrant des modèles dans des milliers de points de données qui sont difficiles à détecter pour les humains", observe Schreurs.
En outre, il voit des opportunités dans la détection des fraudes. Des produits tels que le vin, le miel et l'huile d'olive sont déjà contrôlés aujourd'hui au moyen d'empreintes chimiques, mais l'apprentissage automatique peut déceler des schémas plus subtils et reconnaître plus rapidement les écarts qui indiquent une falsification. Il envisage également la possibilité d'applications pendant la production. Les capteurs qui prennent des mesures en continu pourraient indiquer, à l'aide d'un modèle, la saveur d'un produit avant même que le résultat final n'arrive, ce qui permettrait aux producteurs de procéder à des ajustements en temps réel.
En outre, il a souligné la valeur des techniques d'apprentissage non supervisé, qui révèlent des structures dans de grands ensembles de données sans étiquettes prédéfinies. Ces techniques permettent, par exemple, de distinguer des groupes de consommateurs en fonction de leurs préférences gustatives ou de regrouper des produits en fonction de leur profil sensoriel. Selon Schreurs, ces techniques offrent des possibilités de segmentation des produits, de positionnement sur le marché et même de développement de nouveaux produits répondant à des orientations gustatives spécifiques au sein du marché.
