- 25 november 2025
- Door Rick van de Lustgraaf
Een AI-model om de smaak van voeding te voorspellen
PhD-student Michiel Schreurs – keynotespreker tijdens Food Process Seminar

Michiel Schreurs, doctoraatsonderzoeker aan het VIB-KU Leuven Centrum voor Microbiologie, begon zijn presentatie met de vaststelling dat smaak een van de meest fundamentele, maar tegelijk moeilijkst te vatten eigenschappen is binnen de voedingsindustrie. Hoewel bedrijven al decennialang investeren in analytische technologie en procescontrole, blijft de beoordeling van smaak grotendeels afhankelijk van menselijke panels.
Smaak voorspellen: consistenter en efficiënter
Die panels geven een rijk en genuanceerd beeld van de consumentenbeleving, maar brengen tegelijk grote uitdagingen met zich mee: ze zijn duur om te organiseren, tijdsintensief, en bovenal inherent variabel. Geen twee panelleden proeven precies hetzelfde, en dezelfde persoon proeft zelfs op verschillende tijdstippen niet identiek. Volgens Schreurs neemt dat subjectieve karakter niets weg van hun waarde, maar creëert het wel een blijvende vraag naar methoden die smaak consistenter en efficiënter kunnen voorspellen.
Wie is Michiel Schreurs?
Michiel Schreurs is een doctoraatstudent aan het VIB-KU Leuven Center voor Microbiologie in Leuven, onder leiding van professor Kevin Verstrepen. Hij bestudeert hoe de chemische samenstelling van bier bepalend is voor de bijhorende smaak, met een specifieke focus op hoe lekker we (alcoholvrij) bier vinden. Zijn werk verbindt analytische chemie met sensorisch onderzoek door middel van machinelearning.
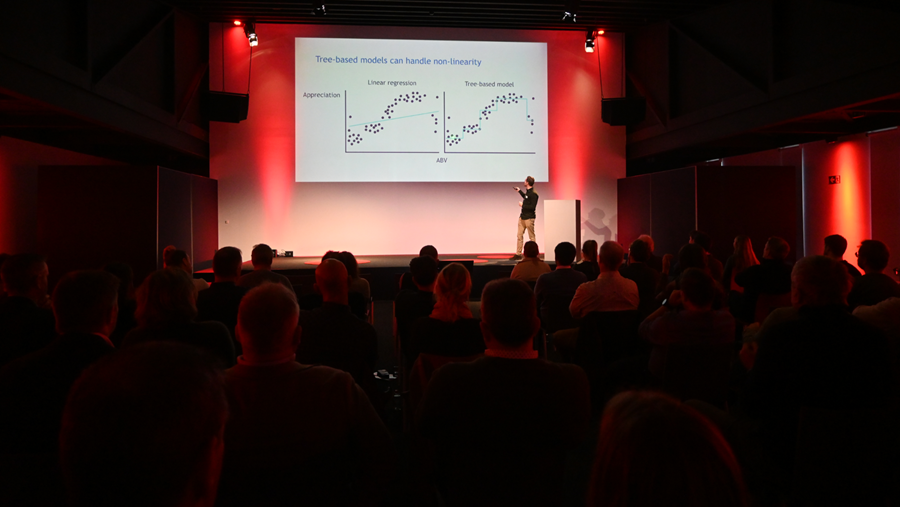
 Er is, stelt Schreurs, een spanningsveld tussen klassieke statistiek en de realiteit van smaakdata. De voedingsindustrie werkt al jarenlang met regressiemodellen om smaak te koppelen aan chemische gegevens of procesparameters. Zulke modellen gaan echter uit van vereenvoudigingen: ze veronderstellen lineaire verbanden, monotone effecten en beperkte interacties tussen variabelen.
Er is, stelt Schreurs, een spanningsveld tussen klassieke statistiek en de realiteit van smaakdata. De voedingsindustrie werkt al jarenlang met regressiemodellen om smaak te koppelen aan chemische gegevens of procesparameters. Zulke modellen gaan echter uit van vereenvoudigingen: ze veronderstellen lineaire verbanden, monotone effecten en beperkte interacties tussen variabelen.
In werkelijkheid is smaak juist een sterk niet-lineair fenomeen. Twee componenten die apart weinig effect hebben, kunnen samen plots een uitgesproken smaakimpressie creëren, terwijl andere combinaties elkaar net volledig maskeren. Dergelijke complexe interacties vallen moeilijk te vatten in traditionele modellen, waardoor voorspellingen vaak onnauwkeurig of inconsistent worden.
Machinelearning
Vanuit dat knelpunt introduceerde de onderzoeksgroep waar Schreurs deel van uitmaakt machinelearning als een veelbelovend alternatief. Hij benadrukte dat het hierbij niet gaat om ondoorgrondelijke black boxes, maar om modellen die zich beter aanpassen aan de onderliggende structuur van de data.
Beslissingsbomen vormen de kern in de studie. Zulke modellen splitsen de data telkens opnieuw op in homogener subgroepen, waardoor niet-lineaire en samengestelde effecten op een natuurlijke manier worden mee opgenomen. "Deze technieken zijn ondanks hun reputatie niet per se complexer dan klassieke statistiek. Ze volgen andere principes, maar zijn conceptueel vaak intuïtief en vereisen vooral zorgvuldige evaluatie", stelt Schreurs.
Meer dan vierhonderd bieren
Het onderzoek zelf vertrok vanuit een grote dataset van meer dan vierhonderd commercieel verkrijgbare bieren. Voor elk bier werd een uitgebreide chemische analyse uitgevoerd en daarnaast werd het geproefd door twee volledig verschillende bronnen: een intern getraind smaakpanel en een brede groep consumenten via online reviews. Door panelgegevens te combineren met consumentendata kon de onderzoeksgroep twee vragen tegelijk aanpakken: of modellen de perceptie van smaak kunnen voorspellen en of de bron van de data invloed heeft op de prestaties.
Schreurs legde uit hoe de dataset werd opgesplitst en maakte daarbij duidelijk dat een correcte scheiding tussen trainings- en testdata essentieel is om betrouwbare modellen te ontwikkelen. Van elk van de meer dan vierhonderd bieren werden zowel chemische parameters als smaakbeoordelingen verzameld. Vervolgens werd een vast deel van die bieren – doorgaans zestig tot tachtig procent – toegewezen aan de trainingsset.

Dit is de subset waarop het model leert welke chemische patronen corresponderen met bepaalde smaken. De resterende bieren werden volledig buiten het trainingsproces gehouden en vormden de testset. Die testset fungeert als een soort examen: het model heeft deze bieren nooit eerder 'gezien' en moet dus op basis van zijn aangeleerde kennis voorspellen hoe ze zouden scoren op verschillende smaakdimensies.
"Deze aanpak is nodig om overfitting te vermijden", zei Schreurs. "Een model dat te nauwkeurig aansluit op de specifieke patronen in de trainingsdata, maar diezelfde nauwkeurigheid verliest bij nieuwe samples, lijkt tijdens de training uitstekend te werken maar faalt zodra het in een echte industriële context moet worden toegepast. Door de dataset strikt op te splitsen en pas helemaal op het einde te testen, wordt zichtbaar of het model werkelijk generaliseert."
Geen toevallig gunstige datapatronen
Zo zijn er duidelijke verschillen tussen klassieke statistische methoden en machinelearning: lineaire modellen leken tijdens de training redelijk te presteren, maar zakten in elkaar op de testset, terwijl de boomgebaseerde modellen hun prestaties grotendeels behielden.
De onderzoeksgroep maakte gebruik van herhaalde crossvalidatie tijdens de training, waarbij de trainingsset zelf meerdere keren wordt opgedeeld in kleinere deelsets. Zo wordt vermeden dat toevallige fluctuaties in de data leiden tot overschatting van de modelkwaliteit. Pas wanneer een model in al die herhaalde tests consistent presteerde, werd het ingezet op de definitieve testset. Zo konden Schreurs en zijn team de resultaten met meer zekerheid toeschrijven aan de werkelijke voorspellende kracht van het model en niet aan toevallig gunstige datapatronen.
Basis voor betrouwbare toepassingen in voedingsindustrie
Volgens Schreurs is deze methodiek niet alleen relevant voor onderzoek, maar vormt ze ook de basis voor betrouwbare toepassingen in de voedingsindustrie. Bedrijven die machinelearning willen integreren in hun kwaliteitscontrole moeten dezelfde discipline aanhouden: geen model mag worden beoordeeld op gegevens die het tijdens de training al heeft gezien. Alleen zo kan men voorspellen hoe een model zich zal gedragen wanneer het in een productieomgeving wordt ingezet.
De resultaten toonden volgens Schreurs een opvallend contrast tussen verschillende smaakdimensies. "De algemene appreciatie van een bier, die vaak sterk door persoonlijke voorkeur wordt beïnvloed, bleek toch verrassend goed te voorspellen." Echter, enkel wanneer gebruik werd gemaakt van de grote hoeveelheid online reviews. De interne panels, hoe getraind ook, bleken te weinig deelnemers te hebben om een even robuust signaal te genereren. De variatie binnen de panelgroep was te groot in verhouding tot het aantal proevers, waardoor het model minder vaste patronen kon herkennen.

Interpretatietechnieken
Voor meer specifieke smaakcomponenten, zoals de perceptie van alcohol, waren de resultaten volgens Schreurs enorm goed. Modellen slaagden erin om met kwadraatwaardes haast perfect te voorspellen hoe alcoholisch een bier zou smaken, wat een enorme vooruitgang is in vergelijking met traditionele regressiebenaderingen. Die hoge prestaties zijn volgens hem deels te verklaren doordat percepties zoals alcohol minder afhankelijk zijn van individuele voorkeuren en sterker gelinkt aan chemisch meetbare componenten.
Om het vertrouwen in deze modellen te vergroten, werkte zijn onderzoeksgroep intensief aan interpretatietechnieken die inzicht geven in hoe het model tot een bepaalde voorspelling komt. Via analysemethoden kon het team visualiseren welke chemische stoffen het model als bepalend beschouwde voor een specifieke smaak. Volgens Schreurs zijn die inzichten niet alleen academisch interessant, maar hebben ze ook een praktische meerwaarde.
Modellen slaagden erin om met kwadraatwaardes haast perfect te voorspellen hoe alcoholisch een bier zou smaken, wat een enorme vooruitgang is in vergelijking met traditionele regressiebenaderingen
In experimenten waarbij bepaalde componenten aan alcoholvrije dranken werden toegevoegd, bleek dat de modellen effectief de juiste richting uitstippelden: toevoegingen die volgens het model een alcoholische indruk zouden versterken, bleken dat in sensorische testen ook daadwerkelijk te doen. Daarmee werd de modeluitkomst experimenteel bevestigd, een belangrijke stap om industriële partners te overtuigen.
Kwaliteitscontrole en fraudedetectie
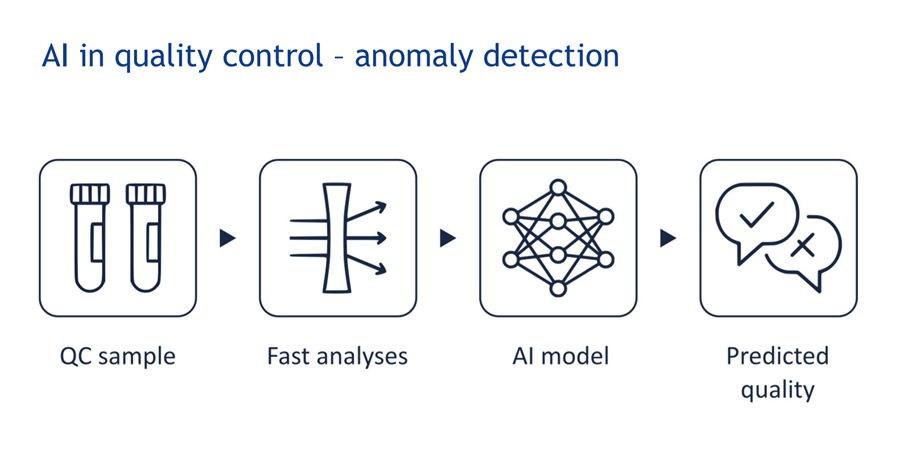
Ruimte voor toepassingen zag Schreurs in meerdere domeinen. Kwaliteitscontrole kan volgens hem een eerste stap zijn. Veel bedrijven beschikken over historische datasets met chemische analyses, procesvariabelen en bijbehorende smaakbeoordelingen. "Dat zijn precies de omstandigheden waarin machinelearning kan uitblinken: door patronen te ontdekken in duizenden datapunten die voor mensen moeilijk te detecteren zijn", ziet Schreurs.
Daarnaast ziet hij mogelijkheden in fraudedetectie. Producten zoals wijn, honing en olijfolie worden vandaag al gecontroleerd via chemische vingerafdrukken, maar machinelearning kan subtielere patronen oppikken en sneller afwijkingen herkennen die op vervalsing wijzen. Ook toepassingen tijdens productie acht hij haalbaar. Sensoren die continu metingen uitvoeren zouden via een model kunnen aangeven welke smaak een product zal hebben nog voor het eindresultaat er is, waardoor producers realtime kunnen bijsturen.
Verder benadrukte hij de waarde van onbewaakte leertechnieken, die zonder vooraf ingestelde labels structuren in grote datasets blootleggen. Zulke technieken kunnen bijvoorbeeld groepen consumenten onderscheiden op basis van smaakvoorkeuren of producten clusteren volgens hun sensorisch profiel. Dit biedt volgens Schreurs kansen voor productsegmentatie, marktpositionering en zelfs voor het ontwikkelen van nieuwe producten die inspelen op specifieke smaakrichtingen binnen de markt.
